This is a Request for Comments (RFC) for replacing Snowplow’s Clojure Collector with an alternative event collection approach for the Snowplow batch pipeline.
We welcome feedback on all of our RFCs! Please respond with your thoughts and comments in the thread below.
Why we created the Clojure Collector
We created the Clojure Collector in January 2013 as an alternative to our CloudFront pixel-based collector. The Snowplow community liked the CloudFront Collector for its ease of setup, essentially unlimited horizontal scalability and zero maintenance. However, over time the functional limitations of the CloudFront Collector had become clear, including:
- The inability to set a tracking cookie on the collector endpoint
- The lack of
POSTsupport, restricting us to sending only one event at a time viaGET
We had also started to run up against some non-functional challenges, including:
- Unexpected changes to the underlying CloudFront access log format breaking our Hadoop Enrich process
- Unexplained delays in CloudFront logs arriving in S3
For these reasons, we elected to design and build an alternative collector for the Snowplow batch pipeline.
It was important that the new collector support a tracking cookie, support POST, and use a logging format that we could control. However, it was also important that the new collector be very scalable, easy to setup and upgrade. From these requirements the Clojure Collector was born.
The Clojure Collector architecture
The Clojure Collector has an unusual architecture, designed to meet the above functional requirements whilst also aiming to minimize the collector’s support burden.
We designed the Clojure Collector (“CC” for the rest of this RFC) around running in Elastic Beanstalk to make deployment and operation easier. At the time, Tomcat application server was the standard deployment target for Beanstalk web applications.
Whilst evaluating Beanstalk with Tomcat, we noticed an interesting thing, namely that Beanstalk had built-in support for rotating the Tomcat server logs to S3 once an hour. We also saw that the Tomcat hosting your Beanstalk application was highly configurable, even down to altering the logfile format.
From this we came up with an unorthodox two-part design for the CC:
- We would write a simple Tomcat servlet that would be responsible for setting the collector cookie and any other required behaviors in the request-response loop
- We would replace the standard Tomcat logging with a customised one with our preferred format for incoming Snowplow events (both GET and POST)
This design is set out in this diagram:

While the design was technically complex, it was operationally simple: we were leaning on Beanstalk itself to do our log rotation of raw Snowplow events to S3.
We chose to write the Servlet component in Clojure as a pilot for that technology. The pilot was a partial success: we never re-wrote the CC in another language, but we never wrote another Snowplow sub-system in Clojure.
The innovative design seems to have worked: the CC is today the most popular Snowplow collector for both the open source community and our Managed Service customers. And on Discourse, the CC accounts for a relatively low share of support queries relatively to our other sub-systems.
However in the years since its launch some limitations have emerged with the CC, which lead us towards replacing this collector. These limitations are set out in the next section.
Rationale for replacing the Clojure Collector
The first reason for replacing the Clojure Collector is around the logging to S3. By outsourcing this logging to Beanstalk, we have given up a lot of flexibility.
For example, we cannot change the logging frequency from once an hour to perhaps every quarter hour, which would be ideal for frequent pipeline runs. We cannot change the logfile compression to something which is more performant in a Hadoop/Spark environment, like splittable LZO. We cannot address infosec requirements such as encrypting the event data at rest.
While the hourly logging approach is predictable, it means that our raw event logs sit on unbacked-up servers for up to an hour before they are saved off to S3. This adds some risk into our pipeline’s “at least once” guarantees.
The second challenge is around the operational control (or lack of) that we can have around Elastic Beanstalk. Beanstalk is designated as an abstraction layer on top of EC2, Autoscaling Groups and Elastic Load Balancers.
While this can be great for newcomers to AWS, at a certain point this creates more problems than it solves:
- We have seen new Beanstalk solution stacks for Tomcat with the log rotation to S3 broken
- We have seen boxes get stuck at 75-80% CPU, failing to rotate Snowplow event logs but never triggering Beanstalk’s health check
- We have tried and failed to add various monitoring solutions to the CC instances without impacting log rotation
The third challenge has been around duplication of development effort across the Clojure Collector and the newer Scala Stream Collector (or SSC).
We built the SSC from the ground-up to write out Snowplow raw events to various stream and unified log technologies, including Amazon Kinesis, stdout and Apache Kafka (as of Snowplow R85).
The challenge is that as new requirements emerge for our collectors, they now have to be implemented in two different places (the SC and the SSC), in two different languages (Clojure and Scala).
For all these reasons, it makes sense to phase out the Clojure Collector and replace it with an alternative. I’ll cover an alternative approach that works today, rule out another approach, and then propose a new design for the community to comment on.
Alternative 1: using the Scala Stream Collector for the batch pipeline
It is possible today to use the SSC to feed events into the batch pipeline. Essentially you would set up a cut-down version of the Snowplow lambda architecture, composed of just:
- The SSC, feeding a Kinesis stream
- Our Kinesis S3 project, reading from the Kinesis stream and writing to S3
You then simply configure your EmrEtlRunner’s config.ymlto use the Kinesis S3 bucket as the aws:s3:raw:in property and set the collectors:format property to thrift.
This is set out below:

This approach has some merit: with the right configs for the SSC and Kinesis S3, we can ensure that events are quickly forwarded from the collector instances to the comparatively durable Kinesis stream, helping deliver our “at least once” processing mandate
With this approach we can also consolidate on one collector codebase, the SSC, and have complete control over how we deploy the components using AWS Elastic Load Balancers and Autoscaling Groups.
However there are some limitations to this approach:
- It’s much more complex to setup than the Clojure Collector
- It requires S3, Kinesis and DynamoDB (for Kinesis checkpointing) all to be available for successful event capture, so it is vulnerable to a service outage
- To handle changes in event volumes you now have to scale three separate components (the collectors, the Kinesis stream’s shards and the Kinesis S3 sinks)
Given these limitations, it’s worth considering alternatives.
Alternative 2: using API Gateway and Kinesis Firehose
What about a “serverless” alternative to the Clojure Collector, using:
- Amazon API Gateway, the hosted API service from AWS
- Amazon Kinesis Firehose, the hosted AWS service which can automatically sink a Kinesis stream to S3
This approach is set out below:
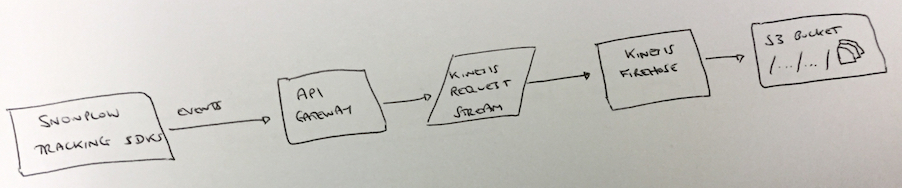
By using these very high-level AWS services, we would be exchanging some control for automatic scaling and simple setup - it’s a tempting exchange.
However there are some challenges:
- We would be back having to maintain two collectors: one for Kafka and this one for Kinesis
- At the time of writing, API Gateway and Kinesis Firehose are not available in all AWS regions (source)
- It’s not clear that the CC’s support for cookies and link redirects would be supported by API Gateway
- Kinesis Firehose’s options for writing Kinesis records to S3 are extremely limited - we don’t believe that it would be possible to write out a Hadoop-optimised format (similar to the output of the Kinesis S3 project) to S3
Our view is that these challenges collectively rule out this option.
Alternative 3: coupling an S3 sink to each SSC instance
An alternative we have been considering is to configure a new collector instance which contains:
- The SSC
- A local message queue, probably NSQ
- An NSQ to S3 sink (not yet written)
The SSC would write all incoming events to a queue in the local NSQ instance, and the NSQ to S3 sink app would be responsible for writing batches of these events back out to S3.
This design is set out below:

There are some advantages to this approach:
- It’s truly horizontally-scalable, with a shared-nothing approach: just add and remove instances from a single Autoscaling Group to handle changes in event volume
- It doesn’t introduce dependencies on additional or immature AWS services - it just needs EC2 and S3
- It’s easy to deploy and configure: we could provide a single AMI in Amazon’s AMI Marketplace, along with instructions on setting this up in an Autoscaling Group with an Elastic Load Balancer in front
- We are back to using a single codebase for event collection, the Scala Stream Collector - and in any case we plan on adding NSQ support to the SSC for Snowplow Mini to use
The main weakness of this approach is that events will sit around on the collector for some time (perhaps 15 minutes) before being stored to S3, and a server outage will cause event loss in that time. To some extent we can mitigate this by:
- Reducing the likelihood of a server outage, for example by adding some highly pessimistic health checking into each collector, taking it out of the Autoscaling Group (to drain and shutdown) in the event of a possible problem
- Reducing the impact of a server outage, for example by using putting the NSQ onto a persistent EBS volume and having a simple tool for recovering the not-yet-stored events from a failed collector’s EBS volume
There is another option we could consider, which is to increase the S3 write frequency to perhaps every minute.
This would generate many more files - with 5 collectors you would be facing 7,200 files a day, which would completely break Hadoop. But this would be a good opportunity to introduce a file consolidation process, for example to reducing each hour’s 300 files down to a single file, in splittable LZO index format.
REQUEST FOR COMMENTS
This is our most open-ended RFC to date - your comments in this thread will have a real influence on the approach that we end up taking to replace the Clojure Collector.
And this RFC will affect a large proportion of Snowplow users over time - so please do give us your feedback! We’d love to hear your views on the alternative approaches set out above, plus of course any other designs that we might have missed.