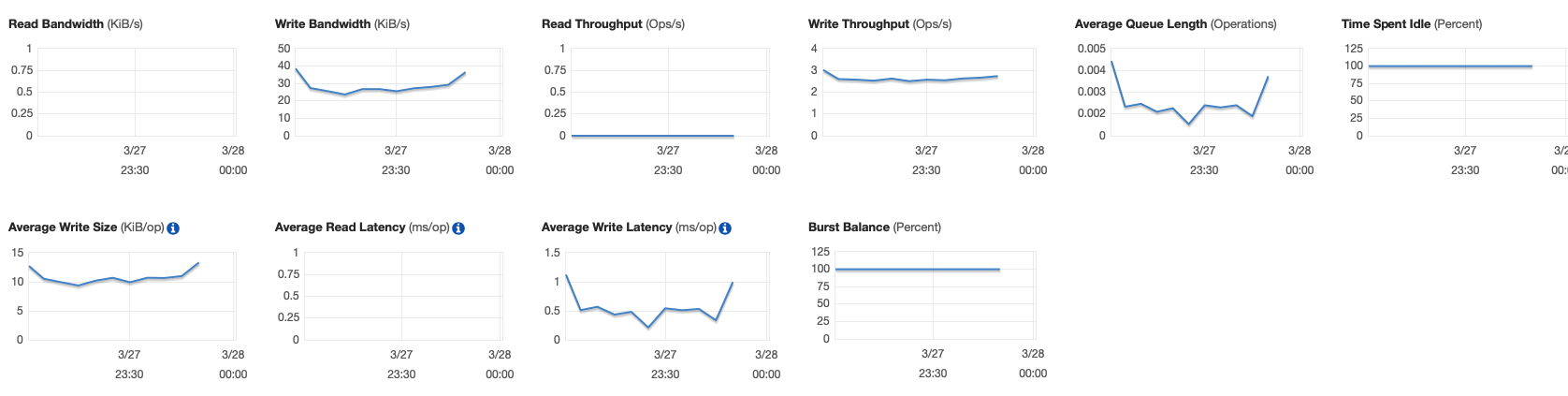
So yesterday we did some stress testing with our Snowplow pipeline, every stage went fine until we reached the Snowflake Loader stage where it would spring up a cluster to process last hour’s events. For one hour of events during our stress test, there are 1121 enriched and gzipped files in the S3 bucket for the good stream from a S3 Loader. Each file averages around 30KB in size as seen below:
We got an EMR cluster with 1 m4.large master and 1 m4.large core to process these events. However, it has been running for 16 hours now and still not finishing it, looking at the task queue, it will take a further day or two to process it.
But the CPU utilisation, memory utilisation, as well as disk space and disk queue length are well below capacity. So it is hard for me to believe the slowness is due to us not having enough instances or powerful machines.
Are you by any chance running the cross-batch de-duplication?
If you do, you should scale the write capacity of your DynamoDB deduplication manifest accordingly.
You should check if you have some throttled requests in your DynamoDB table metrics.
If it’s the case, you should adapt the write capacity to handle the highest spike in writes.
No need for a high read capacity as it’s actually not used by the de-duplication process.
At the moment with a similar configuration I am able to process about 600k events in approximately 70 minutes. This is with bad rows storage enabled too so the first stage (transform) takes about 35 minutes and the second stage (bad row output) 25 minutes.
According to my DynamoDB metrics, the average time per PutItem request is on average 3ms, so in the end it seems that 30 minutes are spent writing events to DynamoDB
I tried to disable the cross-batch de-duplication and the processing then only took 7 minutes (both steps included), so an order of magnitude faster.
The weird thing is that the throughput in DynamoDB does not seem to exceed 300 writes/s, so maybe there is a trick to increase it with some spark tuning?
I am now considering disabling the cross-batch de-duplication from the Snowflake loader configuration and actually doing it as a post processing step within Snowflake.
Maybe someone from the Snowplow team can give us some hints to optimize this step of the pipeline
1121 is a lot of small files. Could you increase the buffer in your s3 loader to write fewer bigger files?
If cross-batch de-duplication is enabled, could you check that throughput is set to autoscaling for DynamoDB, or check DynamoDB metrics like @AcidFlow suggested (i.e. if the maximum write capacity is reached).
Also, for 1 m4.large node your Spark configuration should look like this:
Would in-memory-deduplication slow down the processing a lot as well?
I read on the forum with conflicting information that smaller files are easier for EMR, but maybe that’s wrong? Any rule of thumb as to the optimal file size?
In theory smaller files are not easier for EMR, everything is a trade off. Smaller files means more network IO to read them. Bigger files means less network IO, but then if the file format is not splittable it will have to be decompressed on a single core. However reading your comment on that made me think about my throughput issue.
From our enriched S3 loader we generate about 30 GZIP files a day.
Before running the Snowflake loader, we are archiving it using S3Distcp and I was trying to generate GZIP files of approximately 128MB (which uncompressed was about 1.5GB).
Yesterday I tried to reduce that size to 32MB (which uncompressed is about 450MB).
Having smaller GZIP files reduced my processing time quite a lot (and the throughput to DynamoDB, which then lead to some throttling).
From what I can understand, it is probably due to the fact that GZIP files are not splittable, and somehow results in less tasks processed in parallel (apparently about 1 per GZIP file in my case).
So now I am think about archiving using LZO and increase the file size. This should result in a splittable larger file and Spark could then determine the best partitioning for it.
Do you think this would work @BenB?
When we had the small files, each hourly EMR cluster would need to go through ~1200 files. And the write capacity needed in DynamoDB is easily beyond 1000 units. Scaling this is difficult because when not running an EMR cluster, it needed 0 write capacity, but when running it needs a lot of capacity. The cost of this will add up quickly as well. So in the end we decided to drop cross-batch deduplication and see how it goes.
Do you know any cost and time efficient ways of long-term deduplication in snowflake? Just taking a guess, the more data in there, the slower and more expensive deduplication queries will be.
@pat in-memory de-duplication is way quicker than cross-batch de-duplication as it removes duplicates within the same batch only and doesn’t need to interact with the outside world, as cross-batch deduplication does with DynamoDB, as it is removing duplicates with previous batches. You can find more details about this on this blog post.
@AcidFlow this would be a better approach indeed, but at the moment Snowflake is not able to split indexed LZO files, you can see the related issue on Github. We will need to add this to the roadmap, or if you’re interested in contributing a PR is always welcome
Meanwhile I would say that the most important is that all the cores of the cluster are always reading files. If there are 3 files and 10 cores, given that the files are unsplittable only 3 cores will be reading while 7 are idle. Then I would say that files should have the maximum uncompressed size that fits in the memory available to a core.
Indeed, you would need DynamoDB auto scaling enabled for your use case.
If you can “predict” the time taken by your processing, you could schedule some autoscaling of you DynamoDB write capacity to only increase it when the cluster starts and then scale it down after it finishes (as @BenB suggested).
However if you are running loads every hour, you’ll have to be careful with DynamoDB limitations which does not allow an unlimited amount of down scaling. See AWS Docs about this.
Regarding cross-batch de-duplication in Snowflake, yes the more data there is the slower it would become. But as far as I recall the default cross batch de-duplication sets a TTL for each record in DynamoDB. The TTL is set to 180 days (etl_tstamp + 180 days). After this TTL the item would be deleted by DynamoDB. Therefore if you want to implement the de- duplication in Snowflake, you could limit it to only take into account the past 180 days I guess
I haven’t done it yet, but I can imagine that clustering your table on one of the timestamp columns would probably speed up the processing then.
@AcidFlow this would be a better approach indeed, but at the moment Snowflake is not able to split indexed LZO files, you can see the related issue on Github. We will need to add this to the roadmap, or if you’re interested in contributing a PR is always welcome
Thanks @BenB!
I was actually talking about the input of the Snowflake transformer job.
The output of the transformation produces plain text files for now, so Snowflake can ingest it without problem.
But my S3 loader for the enrich good stream is producing GZIP files. Before running the snowflake transformer I’m moving these GZIP files to a processing directory using s3-distcp. My idea is to convert the GZIP files on the fly during this moving process and generating LZO files for the snowflake transformer to ingest it.
However after a quick try yesterday it seems that LZO generated from s3-distcp are not indexed automatically and therefore do not increase the parallelism. Which probably mean that if I want to achieve that I would have to copy the LZO files to HDFS and run the indexing (using hadoop-lzo) before processing them.
I also added support for splittable LZO in a custom build of the snowflake-transformer and did a test run with it. It resulted in better performances without having to tweak the file size
So thanks @BenB for pointing me to the AWS sample!
I opened a pull request with these changes, but I still need to ask my employer consent for my contribution. I’ll try to sign the CLA as soon as possible.
You can write indexed LZO files instead of GZIP files directly with Snowplow S3 loader, see.
I am already using LZO for the raw good events (serialized as Thrift records).
However I remember running into some issues when using LZO from the S3 loader for enriched events.
As far as I recall (and I’ll need to double check) but with an older version of the snowflake-transformer I could not ingest LZO generated from the S3 loader as it was not able to split it per line.
I will give it a try locally but I remember that the GZIP Serializer writes the record and a \n for each record whereas the LZO is just writing the record itself.
If enriched LZO files produced by the S3 loader can’t be read, this is a bug that we need to fix in the S3 loader. Please let us know if you find out that this is the case. Thanks a lot for all your help!
Which would expect the LZO file content to be some raw text.
But as the S3 loader output LZO as protocol buffer payload, it would not properly read it.
To make it work with the S3 loader LZO output I had to include the elephant-bird library and change the reading to the following:
val hadoopConfig = sc.hadoopConfiguration
hadoopConfig.set("io.compression.codecs", classOf[LzopCodec].getName())
hadoopConfig.set("io.compression.codec.lzo.class", classOf[LzoCodec].getName())
MultiInputFormat.setClassConf(classOf[Array[Byte]], hadoopConfig)
sc.newAPIHadoopFile[
LongWritable,
BinaryWritable[Array[Byte]],
MultiInputFormat[Array[Byte]]
](jobConfig.input).map(b => new String(b._2.get()))
So for now the MR I opened only works if you use the GZIP encoder for your enriched events and convert the compression using s3-distcp.
A fix could be to give a hint to the s3-loader about which stream it is processing to produce the same output but with different compression. This would produce a consistent output for each kind of stream and define the input format for the next pipeline steps.