Hi all,
We have improved a little bit our batch-pipeline peformance this way.
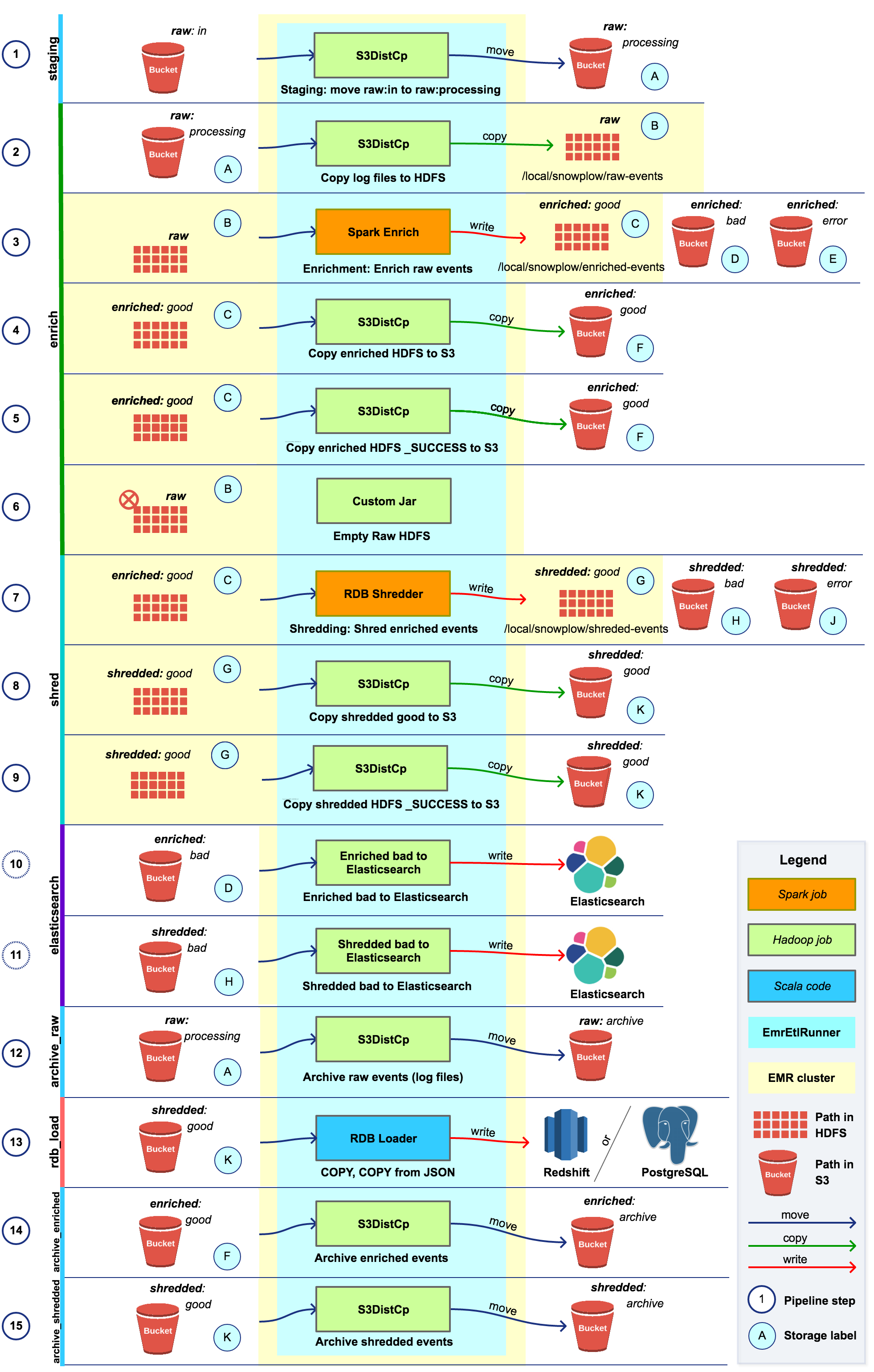
Archive step
If for any reason the server running the EmrEtlRunner pipeline is in a different region than the “archive_enrich” step (Step 12 in the image) then the performance could be impacted, even if the source (:good) and target (:archive) buckets are in the same region.
Here below you can see what was our performance when using 2 different regions and when using only one.
-
Different regions : Peaks of 10k network packages during the archive step

-
One region : Peaks of +30k network packages during the archive step

{kind=link}
Clojure tracker
If your collectors are in different regions, logging into S3, we recommend to enable the S3 Cross-Region replication to sync the files into your :raw:in bucket